




 Companies 2025")
 Companies in Asia/Middle East")
 Europe-Based Firms You Can Trust")
 US-Based Firms You Can Trust")













Andy Ellis, the Chief Security Officer at Akamai Technologies, gives a keynote at ‘Hack in the Box Amsterdam’ event, providing an in-depth view of the concept of present-day information security, its goals and constituents.
Let’s start off with defining the security poverty line; the security poverty line is the term coined by Wendy Nather of the 451 security group.
The idea here is that organizations that don’t have enough resources to do even the minimum security that everybody would look at them and say: “Well, you have to do this. You have to run antivirus. Whether you think antivirus is effective or not, you have to run antivirus. You have to look at your log files. You have to have a firewall. You have to have an IDS.”
And at some point you look around and you say: “Well, there’s me and there’s my EUR7300 budget; how am I supposed to do any of this? Let alone all of it.”
So, what happens is you run into this mindset, that we call the Security Subsistence Syndrome – and what this says is since you can’t even do the barest minimum to cover your own ass, all you’re going to do is cover your ass. Because the last thing you want to have is someone say: “Well, you didn’t install antivirus and instead you were off playing with this weird open source technology that none of us have heard about.”

Nobody ever got fired for buying IBM AntiVirus, pick whatever it is, and that’s what drives this mentality – the mentality that when you think you can’t do enough, that you’d better not do anything different. And different is what security needs to be about, it’s what we have to do to go forward. Because if we don’t, what we’re going to do is we’re going to start accruing technical debt. Technical debt is that work that you cast into the future, it’s just like deficit spending; it’s deficit spending about your engineering. If you build something and you intentionally leave a capability out for the future – that’s technical debt and you’re going to have to come back and fix it if you don’t make your software maintainable. If you leave anything undone, in the future you have more risk, and the future is going to get much harder.
And what makes technical debt very painful is that you very rarely know that it exists. In fact, in most companies the people who keep track of technical debt have very high turnover. It’s very unusual; I’ve actually worked for Akamai for 12 years, so every bit of technical debt that happened on my watch – we wrote down. We know about 12 years of technical debt that faces our business and what we’re going to do about it. Average longevity in the security industry for a chief security officer doesn’t even hit 2 years. We turn over the people who might keep track of this; this increases our risk.
So, that’s a little bit about the security poverty line. Now let’s figure out how to measure it, or how to at least think about it. First, let’s talk about security value. What value do we bring to our organizations when we’re defending them? So, I’m going to define the value quite simply: your resources multiplied by your capabilities; how well you can leverage those resources.
Resources – that’s an easy one: time and money; the time of the people that you have to implement things, and it’s the money you have to go buy stuff.

Capabilities is a little bit harder, three things are going to capabilities: it’s your skill, it’s your effort, and it’s your effectiveness. Your skill – that seems pretty easy: if I ask you to go implement a firewall, do you know how Cisco IOS works? Do you know how NetWitness works? Do you know how any of these technologies work, or do you have to go learn?
Your effort is how you will apply yourself, also seems pretty easy. This doesn’t mean working 80-hour weeks, although most of us probably have that addiction in our systems. This actually means going and doing the work in a timely fashion.
Effectiveness is the interesting one. How do you measure being effective? Sometimes that’s not beating your head against the wall; sometimes it’s about your environment. In fact, last year we looked at our effectiveness. Our information security team at the time was 11 people. And we had 5 of them focused on enterprise security: just our corporate network. We’re one of the largest cloud businesses in the world, and we had half of our security team just thinking about our corporate security, not even thinking about our production network.
And we looked at it like this: “Why are we so ineffective that half of our resources have to be focused on a problem that everybody faces? And only half of them are doing then all the work.” And we actually realized it was environmental; it wasn’t about those 5 people, it was about the fact that they worked for information security, and not for our CIO. And every time they came in and they said: “This is what you should do”, the people in that organization said: “Why is an outsider telling me what to do? I don’t want to do it.” They weren’t that explicit, but that was the behavior you see. And that’s what you expect to see in most organizations.
And if they didn’t come in and tell them what to do, then later they would say: “Well, you didn’t give us any guidance. How are we supposed to know what to do?”
And so, what we did a year ago is we handed those 5 people to the CIO. We said: “You have your own security organization now. They are about twice as effective now as they were.”
Didn’t get rid of anybody, didn’t change that organization: twice as effective just because of an environment. This is very important to measure, very important to understand, because every CFO in every business has a qualitative view of your capabilities. In fact, that’s where they’re going to go put their resources. They will look across your organization and they’ll say: “Well, here’s the median capability of my organization; anybody above it gets more resources, they’re clearly applying them well. Anybody below it, we’re going to take resources away from.”
You don’t have control over your resources; what you have is control over your capabilities. Now, in some sense I’m preaching to the choir, because everybody is here about increasing your own capabilities. You are here to increase your skill. You’re here to make yourself more effective. But many of our organizations aren’t really thinking that way.

How much security value is ‘good enough’? We’d all love to have perfect security; we’re not going to be there though. This graph is not to scale (see image), so please don’t count pixels. But if we think about some point on this line that we will call Good Security, and I’m just going to put it out there as a strongman for a moment, let’s think about what good security might mean in relation to other things.
I think we’d all like to agree that if on Monday a chaotic actor decides to attack you and they conduct an attack on Friday, you should be sufficient against that attack if you have good security. So, clearly, good security is better than what the casual adversary is going to bring to bear.
I think we’ll probably also agree that if you’re worried about a nation state actor, good security probably isn’t enough. Stuxnet is probably going to beat you if you have a nation state adversary, if you have any incorporated adversary. In fact, these probably aren’t the right terms. Probably we want to say Determined Adversary, because it might be that you are faster than your neighbor; you’ve heard that anecdote that you don’t have to be faster than the bear, you just have to be faster than your neighbor. Apple is pretty clearly running faster with iOS than Google is with Android; that isn’t necessarily going to protect them from the rumors of an untethered jailbreak tomorrow.
So, clearly, above this is some concept of Perfect Security, and this is something we have to worry about as an industry: nobody is going to implement perfect security. I have put it here to show that it’s the ideal, it’s a thing we look at, but if you’re implementing perfect security, then you’re taking no risk. Businesses are about taking risk. The goal is: take risk so that you can do something; you can make money, you can be successful. Perfect security means you have no risk. Businesses don’t operate that way, they like to take risk, it’s in their DNA. We’ll talk about that DNA a little bit later.
So, now that we’ve talked about adversaries, let’s talk about, in theory, your partners, who sometimes might be adversarial. So, there are assessors and there are auditors. I like to distinguish them. To me, I want to have a good assessor and a bad auditor.
An assessor is someone you bring in and you ask them to help you. You say: “Please, tell me what I’m doing wrong.” So, somewhere in this, if you bring in a good assessor, they’ll tell you something you’re doing wrong and they could help get you better.
An auditor, on the other hand, has a checklist. They’re doing a PCI audit, an ISO audit, you name it; and they’re doing an audit against it. You don’t want a good one, you want a passing grade. So, if you go hire a competent auditor who is serious in what they’re doing, this is probably where they’re going to get you. They’re using the checklist that was standardized maybe 3 years ago. But before it was standardized, it took 18 months to write.
So, it’s based on a consultant’s view of an adversarial model that is defining risk in terms of return of investment for an adversary, where adversary’s value of your data is the same as your own. And what I think most of us recognize is that what adversaries value is not what their targets value.
Of course, most people don’t hire serious auditors. What they hire is a standard auditor, and then they play a game: “How can we fool our auditor? How can we write down things that are mostly true, spin them in a way that makes us look good, and we will give that to our auditor? And that’s all the security we’re going to do, because that’s all we’re required to do. And so, that’s what we’re going to give to our auditors.” That’s probably what most of our businesses are doing today.
But there’s a line below that. What if you don’t have an auditor? What if security isn’t core to your business? This is what many organizations think they can get away with, even less that what would fool a casual auditor, because they don’t have to hire a casual auditor. Maybe you’re a small merchant and you can fill out a self assessment questionnaire for the PCI DSS standard. You get to write down whether you’re doing enough security. I’m pretty sure nobody is ever going to write down: “I’m not doing enough security; VISA, please don’t give me anything.” I don’t think that’s how it’s going to work. So, that’s basically where these are.

So, I’m going to draw a couple of lines (see graph). The first one I’m drawing is the security poverty line. This is the Cover Your Ass line. If your organization falls into either of those bottom two dots, that’s how you define how much security value you need to have, you’re stuck below the security poverty line, and quite likely you think in terms of security subsistence syndrome: “I am going to do the minimum I can to cover my own ass.”
There’s another line, since I had said how much is good enough. I’m going to posit that good enough is probably below where a good assessor can help you. You’d like to always be able to bring in those good assessors to get better, you use that third party. But if you can fend off a nation state for most businesses, you’re spending too much money on security. Very few people actually run into this problem, so we won’t worry about it.
These aren’t static lines, however; they’re changing. You can see the direction they’re all going. You’ll notice that most of them are going on an upward curve – again, not to scale. The standard auditor and the serious auditor aren’t really changing over time. Anyone who’s been under the PCI regime will recognize that from year to year the PCI standard isn’t substantially changing, despite the fact that adversarial tools have significantly changed in that time.

That’s led to the rise of other technologies (see image) : Havij, its screenshot makes it look like a technology probably from 7 or 8 years ago; but Havij democratized SQL injection. Anybody can download this, point it at a web app and compromise it. Like not being successful enough led to the rise of the High Orbit Ion Cannon, which now you can use booster packs for.
So, what we’re starting to see Anonymous do, another chaotic actors, is telling people: “Here’s where we will release the booster pack. The booster pack is the targeting; we will release it 30 minutes before our operation. Come get it, do an attack, trying to get a faster loop than the defenders get.” Because the problem with having to coordinate in public means that your targets get to watch what you do.
So, instead they release tools that let them get faster, be smarter. And of course, this listing wouldn’t be complete without a screenshot of Metasploit (see image). Metasploit is one of the greatest tools out there, we use it for penetration testing ourselves. But there’s nothing that stops an adversary from using it. In fact, if you go to Metasploit’s community and go look at what people are asking, about half of the questions are from people who are saying: “I want to break into a system, how do I do it?” That’s what the tools are being used for. This rising tide has lifted all boats, and the adversaries are using them more than the defenders. So, that’s why things are getting better for the adversary.
The Peltzman Effect
Why are things getting worse for the organizations? And this comes back to the Peltzman effect. Sam Peltzman is an economist at the University of Chicago, who went into the United States when we were debating seat belt laws: should people be required to wear seat belt while driving? He said: “If you make people wear a seat belt, they will drive faster and kill more people.”
Sam Peltzman’s pretty much right. He says that if you take away risk, people will go and be riskier. NASCAR is a great experiment; for those who are not familiar with NASCAR – it’s a racing car league in the United States, people drive cars in a circle, 500 laps. I’m not really sure what the enjoyment about watching it is, but I can understand the thrill of driving one of the fastest cars on the planet 500 laps in a circle. But it’s an experiment, every year they drive on the same roads, it’s the same tracks; every year we give them better safety technology, and every year they drive more recklessly. There are more accidents in NASCAR than there used to be. They kill fewer drivers, the safety technology works, but the accidents are bigger.

People have this mindset that if you take away risk, they will go absorb more risk. That’s very important to understand, because that’s the way businesses operate. Everybody will take risk if you take it away from them. Would you like to know how to make people drive more carefully? Peltzman had a solution for this: if you’d like people to drive carefully, stick a spike on the steering wheel. If I give you risk, you’ll take risk away. It’s a great model.
None of us would buy a car with a spike on the steering wheel, but I guarantee you everybody would be driving very slowly. In fact, I noticed this: I went for a run yesterday along the canals in Amsterdam. I should have asked somebody what all of the lines were for, because I realized I was running in the bike lanes. Probably not the wisest thing: I almost got knocked into the canal twice.
But I noticed something about bicyclists in Amsterdam: so, I’m from Boston, and in Boston we have tons of bicyclists, and some of them drive really fast, they’re moving more rapidly than cars. And some of them are driving very slowly. And in Amsterdam nobody was riding their bike very quickly. I attributed it to the fact that it was god-awfully warm out; but then somebody pointed out to me yesterday that these bikes don’t really have brakes. You have to sort of pedal backwards to slow the bike down. I didn’t quite grasp what it was, but slowing the bicycle down is hard. If you go fast, you’re at risk of not being able to stop if you need to.
In US bikes you have the handbrakes, just squeeze the brakes and the bike stops on a dime. Works very easily, people drive rapidly. Dutch bikes – you can’t stop, so you don’t drive quickly. You’ve taken risk out of the system by taking away something that brought in safety. None of you wear helmets, that was the amazing thing. In Boston, if you don’t wear a helmet, people look at you and they’re like: “You’re an idiot.” Here, I think if you wear a helmet people would look at you and say: “You’re ruining it, you’re getting hat hair.”
Set-Point Theory of Risk Tolerance
This leads to what I call the Set-Point Theory of Risk Tolerance. Basically said, people can perceive risk; a very important point is that perceived risk is not actual risk. I’m not trying to measure actual risk here; I’m measuring perceived risk. People have a set point that they want to live at. If you take risk away, they will absorb risk to get to that set point. If you introduce risk, they will act to remove that risk.
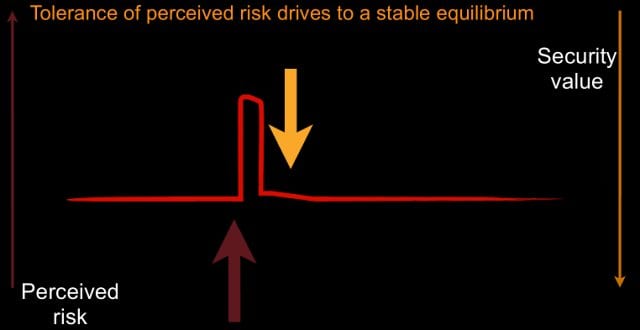
So, we can look at this and say: as perceived risk increases, we will apply security value to push it down. So, that’s why I’ve inverted security value here. It’s the pressure downward, risk is the pressure upward (see image).
We can think about perceived risk possibly as an impulse: we have some event, we’re going along, we get some risk, we act and we close the risk down. You can think about this as incident management: I have a breach, I act to remove the risk that I just discovered, and then I move on.
And you notice we returned to where we started from. We think we’re safe now, or at least as safe as we were going into our incident. This is a good mindset for humans to be in. It’s sort of like a lizard brain inside us: we want to act, we see risk, we deal with it, we move on. That’s how it’s going to operate.
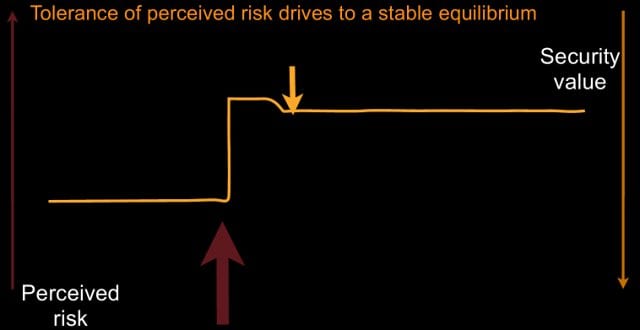
Unfortunately, most of the time we don’t remove risk when we’re presented with it, so instead, what we see is something more like this (see image). We’re going along, we get some risk, we act, and we’re insufficient to remove the risk from our system. And worse: we know it. Now we have a problem: we have more risk in our system than we know what to do with.
Sometimes that perceived risk didn’t increase from an outside force, it increased because one of us went to our boss, we went to the CEO, and we said: “Look, we have more risk in the system. We’ve just discovered this thing we’ve had, and now we have to go fix it, and it’s a crisis.” And so, CEO says: “Great! Do something about it!” And it turns out doing something is very hard. There’s the reason that risk existed, just nobody knew about it.

So, you do some things, and 9 months later it turns out you’re up high. So, what happens? The human brain cannot tolerate this. This is not a state of affairs that is acceptable to it. One of two things happens. One is we tell ourselves a story, and we say to ourselves: “That risk was always there, I knew about it. That episode that I had 9 months ago when you told me about it – that was the aberration. That risk has always been in my system. I have a new set point; I am now comfortable with the risk, let us move on.” Long-lived risk is a problem for you, because this is what will happen: you will change your set point and you will believe you didn’t.
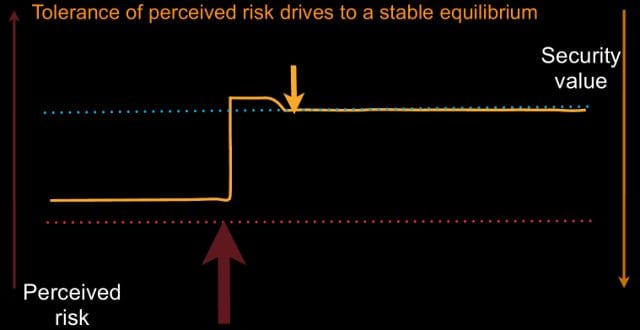
Or, and this is what gets most security professionals in trouble, we tell ourselves a different story: “You’re lying to me; that’s not really a risk. What do you mean this person could do something bad to me? They’ve always been able to, we’ve been in business for 10 years and it still hasn’t happened. So, clearly it’s not as bad as you think it is.” Everybody’s probably heard a story like that before. Or we can say: “Can you quantify? What’s the percentage chance it’s going to happen?” And you say: “Well, 5%.” And somebody looks at it and says: “Well, 5%, we’ve been 20 years, we should expect it to have happened once, it hasn’t, so why don’t we call it 3%? Are you sure it’s not 3%? Oh, good, 3%. Oh, wait, you’re sure it’s 3%, maybe not 1%?” We negotiate ourselves down into a different state, and while we’re doing it you’ll notice we actually got lower. We actually wrote out more perceived risk. Because while we’re doing that, we’re taking our expert and we’re saying: “We don’t trust them; they tell us lies, so we’re going to take more risk out of the system.”
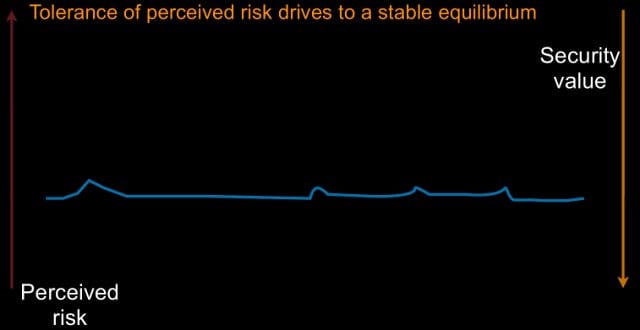
So, what we’d like to see is a way of dealing with problems in a business as something a little bit more routine. We move along; we have some risk – we remove it; we have more risk – we remove it; we have more risk – we remove it; we get into a habit of removing risk from our system in small chunks, it’s digestible, it’s not disruptive. This is how businesses like to operate (see image).
Perceived Risk vs. Actual Risk
Now, I’ve talked about perceived risk, and there is also actual risk. I don’t pretend to be able to measure either one of these, but I would posit that ideal set points are where our perceived risk and our actual risk approximately equal one another. And I think 6 different things can happen here (see image below).
One is the really bad thing: we add risk in, something like an undisclosed breach. You break into my network, you do something, you walk away with it, you go sell that information, and I never find out about it. My actual risk just increased, but my perception didn’t change. So set point theory doesn’t help me here: I don’t act.
Another thing we might look at is known vulnerabilities. Tomorrow Apple is going to go up this way: they have a known vulnerability, they will know about it, their perceived risk and their actual risk, in theory, will move in the same direction. This is good for our brains, we can act with this.
Then, of course, we have everybody’s favorite: fear, uncertainty and doubt (‘FUD’): “Let me scare you with some things that could possibly happen to you. I will make you scared, I will increase your risk perception.” Your actual risk didn’t change. This is one of the favorite tactics of security managers all throughout the industry. It’s really bad, because when you get caught doing this, you have no credibility.
There are some good things that can happen on this as well. Sometimes we fix things. Sometimes we fix things and don’t tell people. These are awesome: perception doesn’t change; actual risk does. Sometimes that’s good. In the long run that’s bad, because at some point somebody will catch up and say: “Oh my goodness, things are much safer than I thought they were. Let’s stop doing security.” But this happens all the time. Sometimes systems that gave you problems get decommissioned and nobody tells you about it. I actually had that happen once. We were tracking a whole bunch of security problems with a system that didn’t exist anymore. And it took us, like, 9 months to find out that somebody had gotten rid of this system for us. We were very happy, we threw them a party.
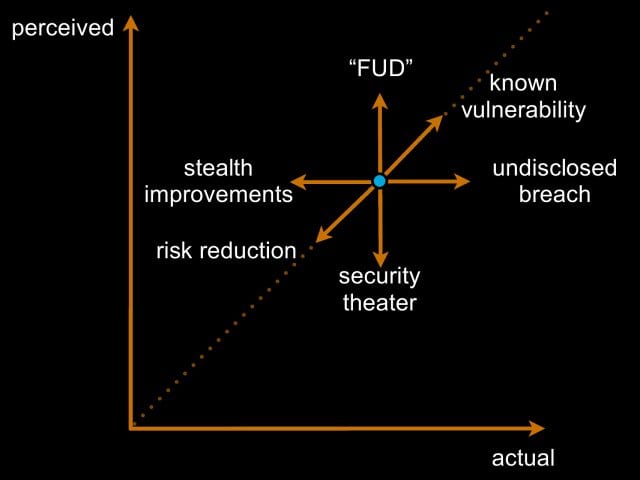
Sometimes you know about your risk reduction. Sometimes you actually manage to line up perception of reality in the good direction.
And finally, we have security theater: activities that we take that claim to reduce risk, that do not. Anybody flown through the States recently? Been through the TSA? Mostly, security theater…I’d say TSA is actually more efficient than BAA’s security, I have to actually give them some props for that. I flew through Heathrow here and it was very inefficient.
Now let’s look at some ways that people act, and I’m going to include a couple of my anecdotes here. First one isn’t me. So, I went and took 3 different terms that I thought would be interesting, and grabbed news headlines. If I wanted more money – and I’m in a habit of begging for money – here’s what I might do.
I might say: “Oh my goodness, look at this, we had a data breach in Utah. The CTO is responsible for that. Mr. CTO, do you want to be responsible for that? I didn’t think so, so we need full disk encryption right now, and a data loss prevention tool. I’m going to go get some money.” People do tend to discover this.

Or I might say: “Hey, look at that, you could suffer a denial-of-service attack. It doesn’t even matter if you’re a for-profit business, we need to go buy DDoS protection right away.” I’m actually in the business of selling that, full disclosure.
Or we might say: “Look, web application vulnerabilities, this is the hot new thing, so we need to get a WAF! And maybe we should have either a dynamic application testing tool or a static one, and look at our coding practices, and see what we can do.” Anybody ever seen any of these dynamics? If you’ve ever actually been marketed by a security vendor, this is what they do. They will walk in and they will throw headlines in front of you and say: “Now buy our technology, because you don’t want this to happen to you.” The problem is, this comes back to that model of creating perceived risk and then not actually reducing it. People stop believing that this might happen.
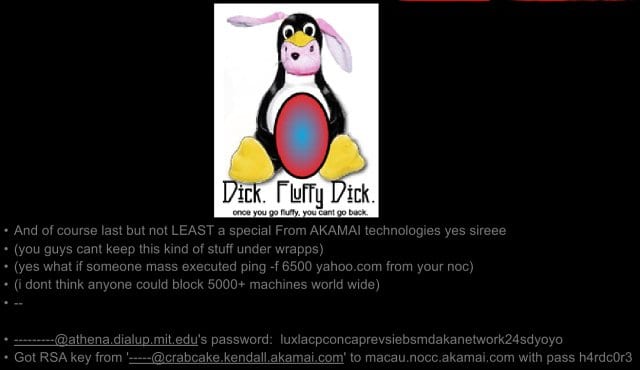
So, instead of begging for money, I would argue that you should waste your crises. This is the real thing; this is a real breach that happened to Akamai 11 years ago. Fluffy Bunny, if everyone remembers Fluffy Bunny, had this really cool SSH Trojan, where they would break into a system, they would get root access, they would replace SSH, and then when you logged into somewhere else, it would record your password, your RSA identity, and your passphrase. And then they would come back again, they would collect those and they would go log into another system using that. Very neat technology. Thank goodness, they had a bug: it didn’t actually overwrite your private key. So, if you used key-based authentication, you were safe, simply due to a coding error. I’ll always take a coding error on the part of my adversaries.
So, they broke into one of our systems, we actually noticed almost immediately, simply due to blind luck. You notice the second to last line here has a password at the end of it, it’s about 30 characters long (see image above). When Fluffy Bunny went to use this to log into MIT, the person’s login scripts automatically started an instant messaging service that sent out a broadcast ping saying they were online. The person was standing in a dorm room of one of their friends when they got the notification that said: “I’m online.” He said: “That’s very odd, because I’m not.” He said: “I only ever log in from 2 places: my laptop, which is in my pocket, and from Akamai.” Clearly, Akamai suffered a breach. He gave us a call, we went, we looked at this, and we dealt with it.
Now, what did it mean to have dealt with this? We could have said: “Oh my goodness, this is a crisis, this requires us to completely change our login infrastructure.” And we actually had people arguing for that, saying that we should take this opportunity to rebuild everything from the ground up. And we looked at it and said: “Well, rebuild everything from the ground up isn’t something we can do overnight. But overnight we can do some pretty simple things. That login server, why is it that people actually get a shell on it, why isn’t it just a pass-through gateway?”

We turned our SSH gateways into VPNs instead. We would still use SSH but they’d behave like the VPN. Now we didn’t have that risk. We changed some of our authentication models. So, we took that and we said: “Here is this big risk; let’s act to bring it back down, let’s make the business more comfortable, and instead let’s take a long-term approach and look at our risks to effect long-term change, because that system wasn’t our biggest authentication risk. This was our biggest authentication risk.”
When I started at Akamai, every single developer had a copy of a root key for logging into every single machine. That’s a way bigger risk than what Fluffy Bunny presented to us. Fluffy Bunny got access to a corporate network machine and stole some source code. I had developers who had left the company that had root access to every machine – this was far more dangerous.
So, we looked at this and we said: “There are lots of possibilities here, and we know what our end goal is, but nobody will let us get there day 1, it’s too hard. But what we can do easily is we can convince people that we need to rotate that key. People left the company with it, we’re going to give out a new one. And, in fact, even better than giving out a new one, we will set up a gateway machine that people can log into, the new one will be preloaded on an agent for you, and if you need to log in somewhere, you can do so. We’re not going to force anybody to change their practices.”
Several developers said to us: “We’d like you to give us the new key, just in case that system doesn’t work.” We said: “Great, the old key is root at Akamai, we will give you a copy of root 2 at Akamai.” It made them very happy, so we did roll this forward and we loaded into those SSH agent root 3 at Akamai. And everybody was able to only get out to the network from those machines; some people were left with their useless key. We told them we’d had a problem in the rotation and moved forward to root 3 instead.
But that was just a step. So, we brought up: here’s a risk, developers have left the business, now we’ve dealt with that risk. Then we said: “Oh wait, we still have that problem. Now we have people who are logging in through the machine, we don’t really know who’s logging in where, and people can log in everywhere. That’s a problem. Now let’s deal with that as a separate initiative.”
So, we built our own SSH application proxy: users now log into our deployed network using their own identities, going through a proxy, which has on it a role-based access control list. It says: “Andy Ellis, you’d like to log into this machine with a read-only account? Well, you have a grant that will let you do that.” And it will pass it through.
But more importantly, it will say things like: “The developers of our mapping software can log into up to 10 mapping machines per day.” We don’t have to specify which 10. As they log in, they get access; when they hit 10, they’re done, letting us enforce least privilege in the same fashion without having operators trying to grant access continuously throughout the day.
And more importantly, our developers view this as an improvement over having to log in through a gateway machine. So, we did a 2-step change that not only dealt with the first vulnerability, dealt with the second one and let me cut out over 99.9% of all access to our deployed network at the time. That was massive.
Now we can actually say things like: “Only a small handful of people can log into even remotely large numbers of machines.” If you just saw one of the previous slides, you saw Fluffy Bunny said: “What if somebody executed a ping flood from 6500 machines?” I don’t have 6500 machines anymore; I have a 100,000 more than that. That’s a very large weapon of mass destruction; I really don’t want even my own employees able to use that weapon.
So, these are ways to think about effecting long-term change: know where you want to end up, and figure out what are the steps to get there that your business will tolerate, because it will not tolerate too much risk reduction either.
Let’s talk about a couple of other problems and things we’ve done to deal with them. Security awareness – anybody here involved in security awareness training? I feel sorry for all of you who raised your hands.

So, this is the problem: we let auditors talk to us about security awareness, and what do auditors say? “Every employee needs to have security awareness training once a year.” And we have to write it down that they took that training. In fact, what’s really funny about this one is: we decided, when we went to SSH keys for our network, that we would have every one of our employees sign a policy about the passphrase requirement for their SSH key, because we weren’t going to monitor, we didn’t want to be able to look at their SSH identities.
So, we had them sign a policy that said they would do it, and our auditors found out they were signing policies, and they said: “We want to audit those policies.” So, by the time they asked us to audit those policies, we had a pretty big stack of paper; there was every policy ever signed, stuck in somebody’s filing cabinet. And when the auditors showed up they said: “Here are 10 people we’d like to see the policy for.”
So, the first thing that one of my employees did was he said: “I’ll put it at least all into in a binder and I’ll alphabetize them,” – made it a little bit easier. But this was ludicrous: we were spending time chasing down pieces of paper that ultimately only our auditors cared about. And we were making people spend time printing it out and sending it back to us and giving it to their managers to sign that they had done so.
So, what we decided is, let’s get the auditors out of the loop of actual awareness training. First thing I have to do is I have to teach people, I have to say: “Look, security is a core principle, everybody has to know that. So, this is our entire security awareness training program from a mandate perspective.” This is it, one webpage (see image).
You go to this webpage and it says: “Why do we care? We care because our customers care. Our customers are doing financial transactions, health care, this is it.” They get to the bottom of this page, and to make sure they know what they’re doing they get a little click sign which says: “Here’s what clicking this means. This means that you have read this policy, you understand how to get more data, because we have links on that page, and you’re acknowledging that you got security awareness training.” And you click the button.

And when you click the button, it goes into a database. And in that database – this is my entry out of that database as of a couple of days ago (see image) – it writes down when you last received that training. This is so effective: you can see how many other departments came to us and said: “Can we use this system too?” Akamai maintains 97.68% compliance with annual security awareness up-to-date training. It took me 2 minutes to go find out that number; those were the only 2 minutes anybody spent overseeing our security awareness program. That’s it.
Now, we don’t stop there, because we acknowledge this is for auditors. But 2 human-minutes per year to go look at how much time is being taken on security awareness training, and about another 3 minutes to go read the page to make sure I don’t need to update it – and that’s all we’re doing. That’s our entire cost. That is security value: we are spending almost no resources, massive capability, and when our auditors show up we have a query that gives them the whole database.
So, when they show up and say: “We want to look at these 10 people,” we say: “We don’t have time to find 10 people. Here’s all 2500, you can go find them.”
Then we go around and we teach people vey specific security awareness things. We teach everybody who answers the telephone at Akamai about social engineering. The recovery, at least within the tech business, has caused us to be targets of social engineering, not from the normal folks you might think about – but from headhunters, they’re calling us all the time; wealth management folks call us all the time.
So, we have a system where, if you get a social engineering call, you send an email about it to socialengineering@akamai.com. It’s not actually quite that, so if you send an email it won’t work. But you send mail to that list – and you’re on that list; if you answer a telephone, you’re on that mailing list. So, as soon as someone calls one of our phone numbers and gets caught, we send mail to everybody else who will answer a telephone, which says: “Here’s exactly what the profile of the attack was; here’s who they pretended to be; here’s what they wanted; here’s how they tried to claim that I should help them.”
And then when they call the next person, the next person is already ready for it. And if you gave something out, send a mail also; we do not punish failure. If you get caught by a social engineer – we expect that to happen from time to time – tell us about it so nobody else gets caught. This is the type of important training to give people. Because we have this training written down for our auditors, they don’t make us write down any other trainings. And that’s the important thing: ensuring that we can provide good value into our business.
Another area we’ve recently been looking at is third-party security reviews. Everybody probably has this, certainly, in these days of outsourcing; your businesses want to move things to the cloud or to some third party. And in theory, your process looks something like this.

We will define a requirement for what we would like to do outside our business. We will then go evaluate some vendors against that requirement. The vendors are probably our friends, the ones that have been taking us golfing, but we’ll ignore that for a minute. Then we will go select a vendor. And once we have selected a vendor, we are going to implement a solution.

At some point in this notional process, we need to get the security team involved and we need to have them evaluate what we’re doing. Now, what we all write down should happen is that the security evaluation should be part of vendor evaluation. If you have 3 vendors that you’re evaluating, you should look at each of those vendors so that you understand the risk associated with them when you make a decision. And that’s what we all write down.
What often happens is that once a vendor is selected, we go evaluate the vendor. We say, well, here is what we know about the vendor. And, in fact, I would argue if you’re doing this, you have a very easy metric of success for your third-party security reviews.
And the metric of success is quite simply this: how often do you change what’s happening? How often does the business say: “Well, we’re not going to go with that vendor”, or you force the vendor to make changes? And if the answer is ‘Never’, which is quite likely what most people run into, then you are providing no security value here, your effectiveness is zero, which negates all of the resources you apply.
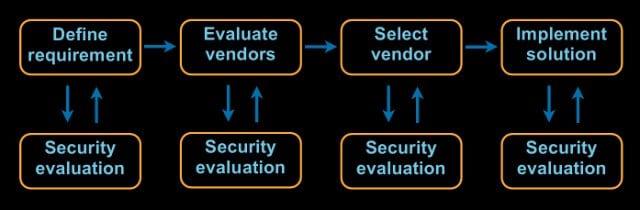
It might even be that you don’t do a security evaluation until the solution has been implemented. When somebody implements something, you find out about it, then you go look at it. That’s usually where you find the most interesting things.
And in the very, very rare case you might actually get to do security evaluation with the requirements designed. What can we do better? What should we be thinking about when we talk to our vendors?
I have different names for each of these faces. If you have to do vendor evaluation security, you are trapped in vendor hell, because business will quickly understand that the right way to deal with you is say: “Well, we’re looking at 15 vendors, can you please evaluate all of them?” Don’t let them do that to you. That’s a little bit painful, because the vendors are not going to give you very useful data and you don’t have enough time to deal with all of them.
Or vendors have already been selected; what you’re really doing here is covering your ass. This is the security poverty line, right there. You’re not actually changing anything; the only reason that you’re doing an evaluation is so that you can tell your auditors you did an evaluation.
I think what our favorite is, for security professionals, is the ‘scapegoat hunt’. You’ve already implemented it, let me go see how I can get you in trouble for all the bad things you did. And since I didn’t have a part in this, I’m certainly not responsible for it.
And then nirvana – business alignment, when we actually get to help define requirements: what are the security needs of the company? This is awesome when you get here. It doesn’t happen very often, but it can. This is where you have the most security value.
Another story. We have a 10 PB cloud into which we store third-party data. Any of our customers can put things into that location. We support FTP for some of our customers, which has its own problems, and many of those customers discover that the computers they’re uploading software from get compromised, and an awful lot of bots will look for FTP credentials and go inject malware into their content.
So, occasionally we find malware in that cloud. 10 PB is not an easy problem. How do you hunt for malware? You cannot go look at 10 PB of content that is fast moving – simply not computationally feasible. So, we’ve looked at this problem for quite a while, we actually ended up open sourcing our work: if anybody wants a copy of it you can go get a copy of it, so I put a URL here for you.
But we actually looked at this and we said: “What is the interesting malware that people would put in a cloud that sits behind web servers?” Some of that interesting malware is malware executables. We looked at the antivirus space for ideas here, and our biggest idea was Don’t Bother. Things that are going to be put in there likely are not going to be spotted by antivirus scanners, and the antivirus scanners are expensive to run.
But we’re interesting, we’re delivering HTML. What do antivirus things not ever look at? HTML. They are looking for executables. But HTML is very interesting: it’s human-readable, it turns out it doesn’t have an awful lot of entropy, and it turns out that most malware writers are writing things that look very unusual to the human eye, or to a computer eye, much more importantly. And they stick out like a sore thumb.

So, this 10 PB cloud is a haystack, but looking for a needle in that haystack isn’t very hard, because malware written into HTML sticks out like a sore thumb, because HTML ultimately is designed to be human-readable, so most obfuscation techniques actually make you stick out even more. If you obfuscate JavaScript so that it can’t be evaluated, which is a standard technique that people will use to deal with people who try to reverse-engineer the malware, you stick out so far from normal HTML that it’s easy to say: “Let me just go find that.”
There are certain things nobody actually uses in JavaScript, so if you put that in your malware hoax, they’re easy to find. So, this was our solution: very lightweight scanner; doesn’t cost us an awful lot to run; very effective at finding indications of malware. Not perfect; we weren’t looking for perfection, what we were looking for was the hint that somebody’s account has been compromised, that would let us work with them to clean up what they were doing inside our system – solving a problem very easily, very cheaply, very efficiently. And that’s what security value really needs to be about.
As security professionals, we have a lot on our plates, we have a lot of things to do. How many people here juggle? If you try to learn to juggle, you start with one ball. You take one ball and you throw it from one hand to the other hand. And you do that for a while, until you can learn to throw the ball from one hand to another hand. And then you take two balls: put one ball in each hand, and you throw one ball, and before the other ball gets here, you’ve got to throw it across and catch it. And you do this for a while until you learn what that’s like. And then you’ll take three balls; two in one hand, one in the other; throw one ball, get this ball out of the way, get this ball out of the way, get this ball out of the way…Juggling three balls is pretty easy, almost anybody can do it.

So, if I give you three things to do, you’re going to be able to juggle those three things. Those three things could be any tasks that you have at hand.
Now, what if I give you five balls to juggle? How easy is that? Is it easier or harder than if I give you seventeen? Which one are you going to be more successful at? The answer that probably jumps into everybody’s head is five, and nobody wants to say it because they know it’s a trick question, because that’s wrong – the answer is seventeen. Because if I give you five things to juggle, you’re now below the security poverty line and you think you can do it, so you will try, and you will fail.
If I give you seventeen, if you’re smart you put fourteen of them down. And now you’re juggling three balls. You failed at fourteen, but you succeeded at three, which is better than you would have gotten with five. And that’s an important lesson: how do we figure out what are the things that we’re going to fail at anyway? Put them off to the future. It’s a very hard thing; our brains don’t want to deal with that, because we know what that risk is.
But if you’re just going to fail, fix something now. Fix something that will give you scalability into the future. 10 years ago I had to do this. Akamai got caught by the dot-com bubble; we laid off 29% of our employees in one day. And that was only one of our reefs; we went through several of them, it was very ugly. We were a 1200 person company; by the time we came out of the bubble we were 500.
I lost half of my security team; in fact, that was the first management thing I got to do. I got put in charge of our security team, there were five of us as peers, I got put in charge of it, and the first thing I got told to do is let two of them go. How do you even make a good decision like that? And then what do you do?
So, we went through this period that we called the ‘lifeboat exercise’. The boat sank, now we’re on a lifeboat, and we’re trying to bail water as fast as we can. We’re taking a lot of risk, and we knew it, because we were losing money quarter after quarter, and there was a very good chance we didn’t have a business at the other end of it. So, what could we do? This is what we did: we dropped the balls intentionally. We said: “This problem is for the future.”
We implemented our own GRC system; I always laugh when people come and try to sell me GRC, because I built it myself. It’s simple: GRC is a spreadsheet. Take a spreadsheet and write down everything you’re casting forward to the future so that you don’t forget it and so that in the future you can go look at that and say: “What are the problems that I have to deal with?”

So, coming back to how to measure security value – the values about resources, times, capabilities – the goal of any security program should be to increase your value over time. If you are not doing that, you’re doing something wrong. You want to provide more value tomorrow than you’re providing today.
However, if you’re below the security poverty line, you probably only think about value in terms of resources: how do I get more time, how do I get more money? This is not a good goal, because if your capabilities are low, people aren’t going to give you more time or more money. In fact, if they view you as an operational entity, by definition you get fewer resources over time. Operational groups are supposed to get more efficient; therefore they need less resources. That’s in everybody’s heads.

If you want to run a good security program, your goal is to create technical surplus: increase your capabilities year after year so that you’re doing more with your resources; figure out how next year with the same amount of resources you will provide more value. I’m not saying: do more with less; even if it sounds like that. I’m actually saying: make yourself more. Make each person smarter year after year. Make each person better able to do their tasks. If your tasks are not effective, stop doing them, go do something else. Do things that provide value to your business; the money will follow.
So, I talked about how a year ago I had eleven people, and we gave five of them to the CIO organization. I’m assuming everybody can do math; that leaves me with six people, right? I have seventeen now, because the organization said: “Well, you’re much more effective, your capabilities are great, here’s more problems for you to go deal with, here are some people to deal with those problems.”
The problems they tended to give came in chunks that you needed three people to solve, and they gave me two people. The organization will never give you enough people to solve your problem; what they were relying on was our proven ability to make those people more effective, to give them better capabilities. They were right, we’re still very busy, I’d love to have more people. But what we focused on is not getting more people, it’s being more capable.

Now I’m happy to take a question or two or five from the crowd, if anybody wants them.
– Hi! My question is: often a big mistake that companies used to make was considering security feature that is a stacked-on layer as opposed to being interwoven in the facets of the organization, and later people came to realize that it actually has to be driven down for management, because it encompasses all of the organization. The trap that many organizations fall into is that they appoint a CSO or CISO, but, like you said in terms of the security poverty line – they just appoint him to look good and they don’t want him to get in the way, so they don’t give him any budget, they don’t give him any authority, so he ends up being a scapegoat. How did Akamai avoid that trap?
– I think how we avoided that trap was a couple of different systems. One is we appointed our CSO from inside, so I didn’t come in as Akamai’s CSO, I came in as a security engineer and worked my way up to being Chief Security Architect, ran our security team, then became CSO. Akamai is a meritocracy, so if you have been there for a while and you haven’t screwed up an awful lot, then there is a very good chance that people will listen to you rather than your title. That’s a big piece of it.
The second one is I don’t say No. I also don’t say Yes. I’ll give you an example for that. We review every single product launch, so every product we take to market gets reviewed by our security team. They don’t say Yes or No. What they do is they provide a grade of Pass or Fail as to whether or not you did a good security job. And if you fail, you can still launch, that’s okay, we’re not blocking the launch. We used to do it though, we used to approve or disapprove a product launch.
Now, imagine you’re the vice president of your product group, and your product manager is trying to launch a product, and the security team is sitting here saying: “Well, we have a problem, because for some reason you folks chose MD5 as your hashing algorithm instead of choosing SHA-1, or we really would have liked SHA-512. Or maybe we can wait for SHA-3.”
And you have a VP of products who’s sitting here saying: “Are you telling me you’re not going to let me launch something that might be worth 250 million dollars to the business, over the selection of a hashing algorithm? How many other places are we using MD5?” And when you answer that with an unpleasantly high number, they say: “Great, I’m not taking any more risk, are you really going to hold up this product launch over that?” And they’re going to put you on the spot, and either you say No, in which case “Well, there is no security problem,” or you say: “Yes,” in which case they overrule you and they’ll build a little cist around you. They’ll say: “We’re not going to listen to this person anymore.”
Neither one of those is a good approach. So, instead we say: “Look, you can launch this product. We’re failing you because for some reason when you decided to choose a crypto algorithm you: a) didn’t read the policy that we have, which tells you which crypto algorithms to use; b) didn’t talk to one of our security architects – we have enough of them to provide you with basic advice like that; and c) waited until you had written it to come for a security review. You have failed on that account, don’t do it in the future. But you can go forward and launch the product. You understand what the risk is now. You understand what you have done.”
Because what happens in a business is I decide I want to do something and I say: “Here is what I’m going to do. Security person, is this safe or not? And I don’t let you tell me about risk. I make you give me Yes or No, and I’m going to ignore your answer. So, any risk that you find out about is risk you have to live with; I don’t have to live with it as a product manager.”
That’s a bad dynamic; the product manager should know what their risk is and say: “Yes, we’re comfortable with that level of risk.” And that’s one of the things that we’ve done to prevent that isolation from coming in: we don’t let ourselves be used as a risk dumping ground.
– So you’re basically taking on more of an advisory role than a go/no go role?
– Absolutely. I don’t have accountability for profit loss line; I don’t get to say Yes or No. I have to give advice because I don’t have accountabilities at the bottom line of the business. If I had accountability to the bottom line, then I get to say Yes or No. But that’s not the business structure.
Thank you!







