






 Companies 2025")
 Companies in Asia/Middle East")
 Europe-Based Firms You Can Trust")












This entry reflects the Black Hat Europe presentation based on the research by Fortinet’s Guillaume Lovet and Axelle Apvrille, dedicated to comparing the human virus defense mechanisms with those implemented in computers.
Guillaume Lovet: This presentation is a bit different from the other talks that you may have attended so far, because basically it’s a comparison between computer viruses and biological viruses. That means we will have to delve into some biological concepts, so we won’t be talking only about computers, for a change. And we do hope that you will enjoy it as much as we enjoyed it when we did the research.

I wrote this paper and did the research with Axelle Apvrille, unfortunately she couldn’t be here today, so I will be assisted by Ruchna here. The paper was reviewed by Koshika Yadava – PhD student in Immunology, so basically she made sure that we would not say too much bullcrap in the paper. We are all part of the Fortinet’s FortiGuard team except for Ms. Yadava of course; basically, FortiGuard team is the threat research and threat response team at Fortinet.

So, the reason behind all that: as I said, when we started we wanted to do a comparison for fun and to please our curious minds, because hackers have curious minds. Basically, we really enjoyed it. Along the way, we figured out that it could help us get a better understanding of why the immune systems in Biology are so much better than the AV systems in computers in terms of virus detection. Granted, some people die because they are infected by viruses, but they never go undetected. They might win over our immune system, but they never go undetected; and we will see exactly why it is so much different from the AV systems, where computer viruses stay undetected for months, for years.
And eventually, along the course of our research, we came to wonder if at some point there could be some kind of convergence between biological viruses and computer viruses. That means computer viruses starting to behave more like biological viruses, and biological viruses starting to behave more like computer viruses, and possibly one crossing the frontier to the other realm and vice versa, which may sound foolish at first or may sound like a bad scenario for a Hollywood movie, but you will see afterwards it’s not so stupid a question actually.

So, this is how we will proceed. First we will go through some background on Biology, which is necessary but not too deep. Then we will compare the attack strategies and defense strategies of biological and computer viruses, and we will see the similarities. And then, as I said, the scary stuff for Hollywood will be in the end with convergence scenarios.
Background on Biological Viruses
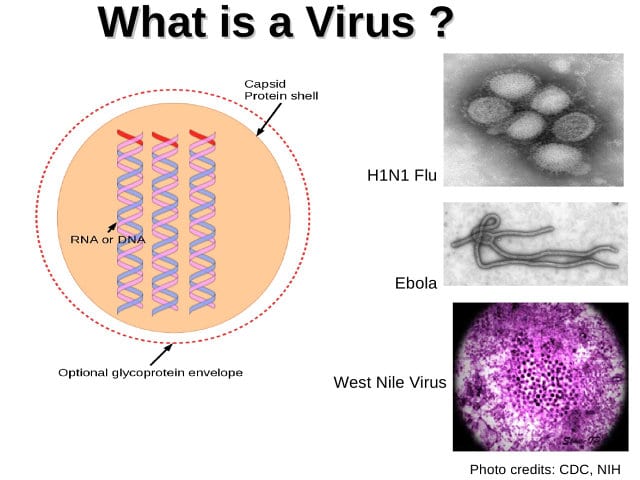
So, biologically speaking, what is a virus? Essentially, it is a strand of DNA or RNA surrounded by a capsid which is a virus shell consisting of proteins (see left-hand image). Those DNA strands contain code for the molecules and proteins that form the capsid.
What is very interesting about viruses is that they are really at the frontier between the living and the non-living. We don’t really know if it is a form of life or not. It depends on your definition of the form of life. Now, most scientists will tell you the smallest form of life is a bacterium, because it is one cell, and all the living organisms are made of cells. So, the smallest possible living being should be one cell, one bacterium.
A virus is not a bacterium because it doesn’t have a metabolism of its own. To exploit, to decode the information in its DNA, it can’t rely on its own metabolism, it must infect a host, a cell, and it’s the cell that will produce and interpret its DNA sequences. So, it has genetic material like all the living beings but it doesn’t have a metabolism; it’s not a cell like all living beings, so it’s, really, in the middle.

So, since it doesn’t have a metabolism of its own, it must attach to a cell to replicate. Once attached to a cell, it injects its genetic material into the cell. In most cases, you will then have a lytic cycle when the genetic material is injected into the cell, and the cell’s metabolism starts to read the DNA sequence and produce the proteins that the DNA sequence coded for. And those proteins will create new viruses, and when there are enough new viruses in the cell, the cell cannot contain them any more, it just bursts, and all the new viruses get loose and will go infect other cells.
Sometimes you will also have lysogenic cycle, where the genetic material is inserted inside the DNA of the cell. And so, when the cell replicates, it gets conserved, at some point it will be interpreted like this and will fall back to that scenario.
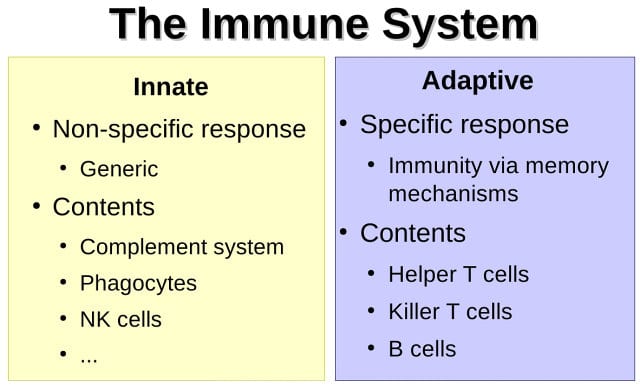
What do we have in our bodies to fight against viruses? (see right-hand image) Basically, the immune system is divided in two different subsystems. You have the innate subsystem, which is the non-specific and generic response, which is made of the complement system, phagocytes, and NK cells – we will go over all that further. And the adaptive system is a specific response. It implements some memory mechanisms, and it’s made of helper T cells, killer T cells, and B cells. We will go over those as well.
Innate Subsystem

So, the complement system (see right-hand image) is perhaps the most complex system and, possibly, not the most interesting. It’s made of large combinations of proteins flowing into the veins, in the blood flow. Those proteins will mark the intruders – viruses or bacteria – by binding to their surface because of some special complementarity. That will attract macrophages, which are part of innate subsystem, too. They will also try to clump and group the intruders, and sometimes those proteins in the complement system will also chemically attack the intruders. So, all those have scientific names: opsonization, chemotaxis, membrane attack complex, and clumping.

More interesting perhaps are the phagocytes (see image to the left). Phagocytes are: granulocytes, in the top left corner, macrophages here, and dendritic cells. Basically, they eat viruses by binding to them. Now, how do they bind to the viruses and then eat them up? They have on their surface some receptors that bind to some proteins or some characteristics on the surface of viruses and bacteria. Generically, they can bind to any virus.
Now, you would think – since viruses and bacteria are supposed to evolve along the Darwinian rules of evolution, which is mutation and selection of mutations that are not deleterious to the organism – that those characteristics that the macrophages use to bind to the viruses would be eliminated by evolution, but it’s not the case because those characteristics are critical, so critical that even though they are deleterious to the virus or bacterium, they are still conserved. So, this is what they call the evolutionary conserved characteristics.
OK, so the macrophages, phagocytes bind to the viruses because of critical characteristics that cannot be eliminated, and then they digest them by chemical reactions. This is a bit like a heuristic engine, if you want to compare this to the computer world. Because it is very generic, it matches all different viruses, it relies on characteristics of viruses. For example, a heuristic engine in the AV world would have flags for usage of specific APIs or some other critical characteristics that viruses cannot really not use.
Also, phagocytes release cytokines, which are some proteins used in communication between cells, to help NK cells. NK cells are natural killer cells. They are part of innate subsystem, meaning that they are generic also. That is kind of interesting because they will bind to viruses and intruders and then kill them by releasing some chemicals.
The way they recognize the viruses is they basically use whitelisting. They recognize everything that is non-self, because all the cells of your body have on their surface a specific antigen, which is called HLA, human leukocyte antigen, which is specific to you only. So, those NK cells recognize when a cell doesn’t have your own marker on its surface; it’s basic whitelisting, if you want to translate it into the AV world.
Adaptive Subsystem
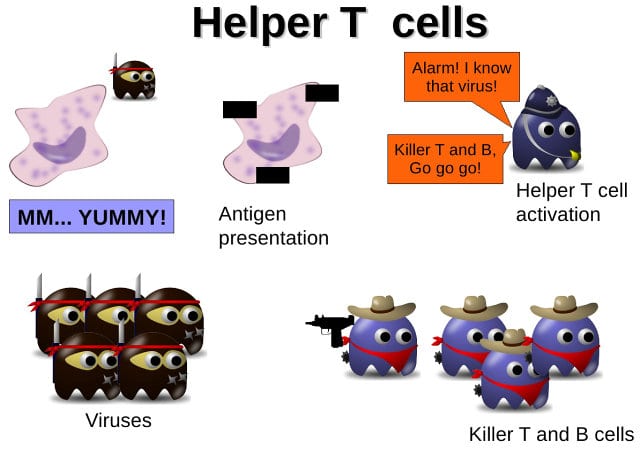
Now, some facts on the adaptive subsystem which is made of helper T cells, killer T cells, and B cells. When the macrophages, part of the innate subsystem, eat up viruses, like I explained above, and digest them with some chemical reactions, some little pieces of the virus remain and they are going to be presented at the surface of the macrophage in the form of antigens. It’s a bit like saying: “Hey guys, I just got that virus, I ate that virus and these are some bits of that virus. Do you recognize it?” Some helper T cells bind to the macrophage, recognize the antigens, and activate the adaptive subsystem.
What is important to understand in the adaptive subsystem is that each T cell – should it be helper T cell or killer T cell – and the B cells, each one of those is specific to one virus only. For example, flu type A – some cells will be specifically dedicated to that virus, and flu type B will be other cells, B cells and T cells. This is because the T cells and B cells have on their surface specific receptors that only match the shape of one virus.

So, killer T cells and B cells eliminate the viruses after being activated by the helper T cells (see left-hand image). Basically, the killer T cells, as I said, bind to the virus because of the specific receptor, and then release some chemicals and kill it. They pretty much function like blacklisting in the AV world, they are basically AV signatures, if you want to translate this into the AV world. Each signature, each pattern is dedicated to a certain virus.
Now, for B cells, those are the ones that are also dedicated to one virus only. When they bind to it they release antibodies. Antibodies are dedicated to one virus only also. Antibodies will bind to the virus surface, and they make it easy for phagocytes, macrophages to spot the viruses. So, I would say, you may compare the B cells to unpacker in the AV world, because it makes it easier for the generic system to spot the viruses. For example, when you have a packed computer virus all its characteristics are hidden and there are some layers of obfuscation.

So, heuristic engines will not see much. They will only see this is packed, they will not see what API it uses, they will not see if it replicates or whatever. So, you need to first unpack the virus, and then the generic subsystem becomes more efficient.
As I said earlier, the adaptive subsystem implements a memory mechanism (see image). So, when the T cells and B cells are activated by helper T cells, they multiply to fight the virus, and when the infection is finished some of these cells will remain as memory cells. So, if the same virus comes in again, they can multiply very fast and react faster. Now I will turn it over to Ruchna.
Ruchna Nigam: Okay, now that you have had your Biology lesson, let’s look at some of the attack strategies that are common between the biological world and the computer world, what I like to call “God vs. Man”.
Outnumbering Defenses
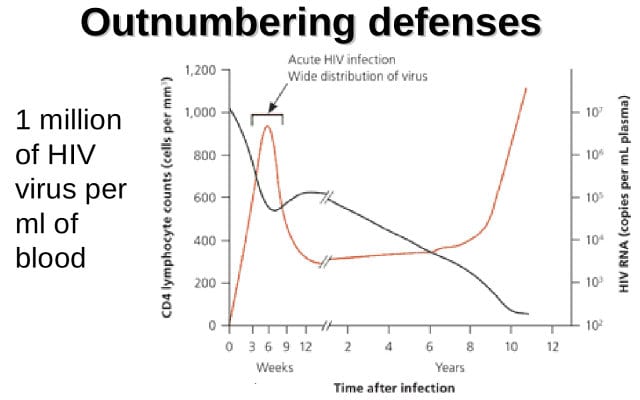
So, one thing we see in common is something called “outnumbering defenses”. What the HIV virus does is it replicates itself to a number that is so high that it renders the defense system of the human body helpless. This can sort of be compared to a denial-of-service attack in the computer virus world, where you overload one resource so much that it fails to function. For example, if I send too many requests to a server, it won’t be able to process those after a while and it loses its basic functionality.

One basic difference between the biological world and the computer world is that human viruses try to overload one host by massively infecting it. This was interesting at the beginning of computer viruses when just infecting someone’s machine was exciting enough, whereas now the purpose of computer viruses is monetary gains. The idea is to propagate to more and more victims to get higher gains. So, this practice is used in a lot of the new worms and botnets (see left-hand image). For example, the Conficker worm managed to infect six and a half million hosts in a short period of four days.
The “Waiting Room” Effect

Another thing we can see in common between human viruses and computer viruses is that there can be instances where the victim actually happens to contact the virus by himself, and manages to get himself infected. For instance, if you go visit a doctor and you find yourself in the waiting room – even though you might not be ill, you are exposing yourself to the danger of getting the flu. This is somewhat similar to what we see in the computer world in the form of drive-by downloads and phishing, in which case the users manage to get themselves infected consciously or unconsciously.
For example, a lot of the new mobile viruses are caught just sitting on highly visited websites. So, you visit it, and you unknowingly get your phone infected. A lot of the new Android viruses come packaged with legitimate applications. You think you are installing an innocent application, like a photo display or something, but actually what happens is it comes packaged with another virus. So, you actually went to the virus and got yourself infected.
Polymorphism

Another thing we can see in common is something called polymorphism. Polymorphism is basically the phenomenon of replicating a virus but making certain changes every time it’s replicated. This wasn’t actually invented by computer attackers, it’s already a phenomenon we see in the world of human virology, where you have something called error checking proteins. So, every time a human virus cell replicates, the body makes sure it’s not too different from the original form.
But what influenza does is it directly attacks these error checking proteins, so basically that means every time the cell is replicated it’s a new form of the virus, and every time it replicates it’s forming a new mutant of itself, which is something we’ve seen in viruses like Koobface and Sality.
The basic difference in polymorphism between the computer world and the biological world is that biological viruses, when mutating, change the basic functionality of the virus, it is possible to change the basic functionality. Whereas in the case of computer viruses, you are only changing the form of the virus, you are not changing the functionality of it, because changing the functionality would require writing new lines of code, whereas all you are doing is changing the package in which it comes.
Virus Mixing
Another thing we saw is something called “virus mixing”. For example, if you happen to have one particular variety of the flu, called flu A, and you got really unlucky and you managed to get yourself infected by another strand of the flu, this could result in the creation of a hybrid variety of the flu called flu C. Basically, you get infected by two separate varieties, but in the end they manage to create a hybrid.
This is something that we also see in computers. For example, if you have a computer that is infected by a mass mailer called MyDoom, what a mass mailer does is it sends out a copy of itself to all the contacts present on your computer. And if you also happen to get infected by a file infector which basically corrupts all the files present on your drive, what actually happens is it also infects the copy of this mass mailer which is present on your drive. When the mass mailer does mail itself to all your contacts, it’s actually mailing a hybrid variety of it, which is the mass mailer infected by a file infector.
Attacking the Defenses

Something really smart that you can see in human viruses is that instead of trying to penetrate the defenses of the body, some viruses actually directly attack the defense. This can be seen in viruses like HIV and Flavivirus. What it does is it attacks your defense system, so there is nothing that can protect you from these viruses.
Something similar can be seen in viruses like Sality, where it dominates all the antiviruses running on your PC, so, again, you are exposed. And what it also does is it adds itself to the authorized applications on your machine, so it’s basically granting itself elevated privileges, and basically you are then defenseless to the virus.
Targeting a System’s Specific Components

In the world of human virology, you see there are some viruses that attack specific parts or specific components of the system. You have the Rotavirus that attacks the small intestine, or Poliovirus that attacks motor neurons. Similarly, in the computer world we have viruses that attack a particular component of the system. There are viruses that attack particular applications, like FileZilla or Internet Explorer, or a virus that attacks the Windows Protected Storage (see left-hand image).
A very good example of this is the Eeki virus for iPhone. What it would do is it would attack jailbroken iPhones and it would verify if the password on the phone is actually the default password, and if it is a match then basically your phone is completely in control of the attacker.
Incubation and Other Time-Based Constraints

Another phenomenon that is in common is something called Incubation. Incubation is the time period between the point where you get infected by a virus and the point where the symptoms of the virus become evident. For example, you might have the flu but it takes about two-three days for the symptoms to be apparent and for you to know that you have the flu.
The same strategy is used in some viruses that are called Time Bombs. They are designed to go off at a particular point of time. For example, the Michelangelo virus back in 1991 was designed to go off on the birthday of Michelangelo. Then you have the CodeRed virus which only spreads itself from the 1st to the 19th of each month and it’s dormant for the rest of the month. This is, again, another idea which has been taken from the biological world.
Sticking with the Target

How these viruses ensure that the system stays infected is also similar between the two worlds. For example, what the HIV virus does is it infects the memory T cells. As Guillaume explained before, memory cells help your body cope better every time you are attacked by a virus. If you are attacked by a particular virus at one point of time, the memory T cells will register that and basically they will help you cope with the same virus better the next time you are infected with it again. What HIV does is it directly attacks these cells, so, that means your body will have no memory of being attacked by HIV.
This is somewhat similar to what we saw in a rootkit called TDL4 which would infect directly the master boot record on a machine. That meant your machine would stay infected even if you reinstalled the OS on it. The ZeuS botnet also makes sure machines stay infected by sending frequent updates, making sure all of its bots have the latest version of the virus.
And the Winner Is…

Until now, we’ve seen that, for the most part of it, God won (see left-hand image). The computer attackers didn’t really come up with very brilliant ideas. Their ideas are mostly already seen in human virology. However, the one area where the attackers did manage to beat God is something called anti-debugging tricks. The essence of this is that the attackers anticipate how the virus might be analyzed or detected by an antivirus company, and they put in measures to prevent this or to make this process somewhat more complicated.
Where Computer Viruses Outperform Their Biological Counterparts

Some of the means of doing this is something called URL redirection. For example, you have this virus called DNSChanger, and if your infected machine would try and connect to an AV website, you would automatically be redirected to another website, which basically prevents you from knowing your machine is infected at all.
Other techniques are detection of some tools such as reverse engineering tools, debuggers, virtual machines, which basically makes the job of AV analysts more difficult. Because if I am trying to run a sample of the virus, and if the virus knows the kind of tools I’m using and what to look for, it might not run or it can hide itself form these tools, making analysis more difficult.
The reason this is possible in computer viruses and fortunately not possible in the biological world is because the code for computer viruses is a lot more complex, it is much bigger in size as compared to biological viruses. For example, if we consider the code for the common flu, it’s about 22 KB, which is merely a fraction of most of the viruses we see.

Guillaume Lovet: The defense mechanisms: we’ve been over some of those already. Detecting viruses inside of the body makes use of heuristics; we saw it was akin to phagocytes, whitelisting – akin to NK cells, and blacklisting – akin to T and B cells, plus antibodies. However, there is an issue with blacklisting, and this is the key difference between the AV world and the immunology world (see image below).
The key is that biological viruses are finite set. There is a limited number of possible biological viruses, it is 10^16. At any time in your body, you have 10^8 different T cells and B cells with the specific receptor matching one virus only. But when some of these die, others are generated with different receptors. Over the course of a few weeks, all of 10^16 possible variations can be covered. And this is why biological viruses are seldom not detected. It would be like in the AV world if the number of possible viruses were finite, and all you would need to have would be 10^16-large database of updates; or possibly 10^8 and then you get circular update so that over the course of a few weeks you check all the 10^16 possibilities.
Unfortunately, that’s not the case: there is an infinite number of possible computer viruses, and this is why sometimes they go through the AV defenses. We fall back to Cohen’s theorem, which is – given an unknown piece of code, the question whether it is a virus or not is not mathematically decidable.
So, the defense strategy of the body is usually to kill everything – intruders, but also infected cells which present the antigens of the intruders. In the computer world, it would be like if you would just kill all the infected computers or reinstall all the infected computers, which we cannot afford to do.
And then, finally, you get vaccines, which are a bit like AV updates, because you present some samples of viruses so that the immune system builds up defenses ahead of time. Basically, you load the adaptive system with signatures, much like AV update.

What we’ve just covered is basically a comparison between biological and computer viruses at the angle of functionality, we compared the functionalities – how they attack, how the body defends, etc. Now, beyond this we may wonder what the essence of a virus is, what its purpose is, and whether it is possible that sometimes the border gets crossed from one side or another.

As I said earlier, a biological virus is essentially a DNA strand. Now, a DNA strand is a sequence of nucleotides: A, G, C, and T. Those sequences code the way proteins are built inside the infected cell. In the end, that DNA strand is information code in base 4 with the nucleotides. The information codes for proteins, and proteins, in their turn, make up the behavior of the virus, because it’s the special characteristics of the virus that make up its behavior. So, in the end you have info coding for the behavior.
For computer viruses, it is coding in base 2: 0 and 1; and this code, when interpreted by an infected host’s CPU, defines the behavior of the virus. So, in the end, both types of viruses are information coding for parasitic and replicative behavior, in base 2 and base 4, but in the end it is the same. So, in a sense, biological and computer viruses are the same (see left-hand image above).

Now, what is their purpose? (see left-hand image) The key when we deal with computer viruses is that they are designed by a conscious intelligence, which defines their purpose: could be making money, doing some espionage, intellectual property theft, or sometimes even destruction of strategic objects, like the Stuxnet worm for example.
On the other hand, biological viruses don’t really have a purpose in the sense that they are the fruit of random mutations playing along the lines of Darwinian evolution. So, unless you believe in intelligent design, biological viruses don’t really have a purpose, but then the same could be said of us, because we are also a fruit of random mutations.

So, we questioned the possibility that at some point we might witness exactly the opposite, which means: biological viruses being designed by conscious intelligence, and computer viruses being Darwinian, playing along the lines of Darwinian evolution.

As a matter of fact, when dealing with designing the biological viruses, the pop culture is full of references to that. You have a number of conspiracy theories that say that AIDS was man-made, which is completely crazy. SARS also is supposed to be man-made. And this is backed up by a couple of scientists actually. If you are interested in that matter, I encourage you to read Wikipedia entry about that. In science fiction you have the St. Mary’s virus. Anyone know what St. Mary’s virus is? It is the virus mentioned in the book and then in the movie “V for Vendetta”, used by the regime to control the population.
Actually, the technology to produce synthetic viruses exists. In 2002, a group of scientists created out of nothing the Polio virus; and later, in 2008, the SARS virus was created out of nothing, synthesized. So, theoretically they could be designed as biological weapons. We have the technology for that. This hasn’t happened so far, to our knowledge – for two reasons.
First, biological weapons are banned under the Biological Weapons Convention. And the militaries think that it is not a very good weapon, in the sense that you cannot really control the evolution of it, and it could backfire at the attacking army. So, they would rather use bacteria like Anthrax which is easier to control. Of course that doesn’t mean that at some point some bio terrorists cannot design a virus to spread fear – it is possible, technically it is not so difficult. This is scary.

On the other end, Darwinian computer viruses have been created already as a proof of concept by some researchers. They call this Evolvable Malware, and unsurprisingly they make use of genetic algorithms, they play along the rules of replication, mutation, selection, like any living being. But they carry a significant dose of intelligent design, to begin with. I mean they were designed like this by conscious intelligence. So, it’s not really what we are looking for.
What we are looking for would be a spontaneous virus evolving out of nothing. In the pop culture, you have this masterpiece called “Ghost in the Shell”, where the flow of digital data is so dense throughout the world that it gives birth to a new form of life spontaneously; this is at the heart of the plot of “Ghost in the Shell”. Could it be possible that a virus evolve out of all digital data flowing through all the wires in the world?
Fact is, according to Cohen, the smallest possible virus would be eight characters long. Aside of that, you have fifteen Petabytes of new info created daily. Among those Petabytes of info, probably at some place, maybe at several different places, we will find those eight consecutive characters accidentally. Now, because those characters exist accidentally doesn’t mean that the virus will take life. You need a CPU to execute those eight characters.
Same Essence, Different Materialization
Now, you guys who are security researches probably know that software is vulnerable. And all these data, generated daily, at some point is processed by software, takes it as an input. And software sometimes, when presented with unexpected inputs, will just crash and direct the execution flow to memory and trigger stack overflow, etc. What if that flow of execution gets redirected accidentally in the memory somewhere to these eight characters? Then you get the virus spontaneously being born.

The probability of this happening is, I think, not null, because there is so much information flowing, and so much vulnerable software also, so it accidently could happen. It would be very interesting to compute, to give an evaluation to that probability, which is a bit out of the scope of this study but will make an interesting research.
So, we’ve seen that computer and biological viruses share the same essence. Essentially, they are the same inside. They are information coding for replicative and parasitic behavior. But this info is materialized differently. In biological viruses it is materialized by molecules, in computer viruses it is materialized by electromagnetic properties. So, the question sounds foolish – can one virus cross to the other realm and vice versa, as they are not in the same material realm?
The Blurred Frontier

If the frontier cannot be crossed, at least it can be blurred. Today people have inside their bodies ear implants, brain stimulators and other cybernetic devices. The more it goes, the more the cybernetic devices will become smart, advanced and will more look like computers with operating system inside them. And what if these computers would be vulnerable to viruses?
As a matter of fact, in 2010 a researcher from a university in Scotland, as a proof of concept, implanted RFID chip under the skin in his hand. He would use it to authenticate at different locations in the university. As a proof of concept, he implanted a virus inside the RFID chip that infected the RFID readers. Granted this is not new, as RFID viruses have been known for years. But that research does prove the point that a virus can hop from the new man to a computer.
And in that case, not really the biological virus that evolved crossed the border; it’s more like the definition of the biological realm that evolved, at least the definition of a living organism within the biological realm, which makes it possible.
Crossing the Frontier

If you really want to cross the frontier, here is some interesting food for thought. We saw that in 2002 some scientists could synthesize the Polio virus. In 2010, another team of scientists led by Craig Venter could synthesize a bacterium out of nothing in a lab. Beyond this, daily, genes are modified, created, synthesized, and injected into living organisms for different applications – this is called bio technologies; for industrial applications to produce drugs; for agriculture and other applications.
Now, all these genes, the sequence that makes those genes, are stored somewhere, they are stored somewhere on computers, in databases on computers. What if a computer virus infects that computer, takes control over the database, injects its own DNA sequence inside? Then you get the lab starting to produce this injected sequence, possibly at an industrial scale. And then you get the virus that hopped from the computer to the biological world.
Conversely, if you want to hop from the biological world into the computer world, it is the same thing. All the labs in the world that map the genomes of living beings, of viruses and bacteria – once they analyze the sequence of nucleotides, where do they store them? In computers, in databases. And you have some software that takes as input the sequence that they found, and of course software may be vulnerable.
Just imagine software that is dedicated to processing the genetic material of a certain type of biological virus, like only the flu for example. So, it expects DNA strand that is 20 KB long. If you synthesize a virus in a lab but its DNA strand is twice longer, and the software fails to check for the length, then when the software starts to sequence the genetic material of your virus, this will create a stack overflow condition. And it can redirect the execution flow somewhere into the database or code for a computer virus. And then you get a hop from the biological world into the computer world.
It sounds like science fiction but it is quite interesting. And actually there would be some motivations to do that. You may want, as for example a terrorist group, to access databases containing genetic material. You may want to do that traditionally through attacking computers and sending computer viruses, Trojan horses or whatever. What if you just do what I just explained – release a virus of your own that will infect the database when it’s being sequenced, take control of the database, and inject some sequence into the industrial genes? That way, the virus would be produced industrially. This is an interesting scenario. And this concludes our presentation.






 Companies in Asia/Middle East")
